
Data Wrangling is the Best Way to Learn Python Foundations
Data wrangling is one of the most effective ways to learn Python foundations because it repeatedly exercises core language concepts in realistic, high-friction scenarios
Introduction
When I first learned Python, I became familiar with its syntax—variables, loops, and functions—but I lacked a deeper understanding of how the language behaves in real-world computational systems. While I could write functional code, I did not yet have a mental model for how Python processes data at scale or how design decisions influence correctness and performance. This understanding emerged through data wrangling. Working with raw, imperfect datasets required me to engage directly with Python’s underlying principles, including data flow, indexing and alignment, immutability, vectorized computation, file input and output, and performance trade-offs. In this context, data wrangling became not just a preparatory step for analysis, but a practical framework for learning Python’s foundational behavior.
1 Data Wrangling Teaches You How Data Flows
Data wrangling grounds Python in reality because it begins with raw inputs and ends with structured outputs. Loading CSVs, reading text files, selecting only necessary columns, and saving cleaned results forces you to think about how data enters, moves through, and exits a system. At the same time, casting columns, choosing between object and string, handling missing values, and reshaping data make data types feel concrete rather than abstract. Together, these steps reinforce the idea that Python objects represent states of data, not just variables in memory. Instead of treating data as something that magically appears ready for analysis, you begin to think in transformations—raw → inspected → cleaned → structured → analyzable. As illustrated in Figure 1, concrete pandas operations map directly onto higher-level stages like input, inspection, transformation, and output. This shift—from writing isolated lines of code to designing data pipelines and transformations—is one of the most important steps in becoming fluent in Python.
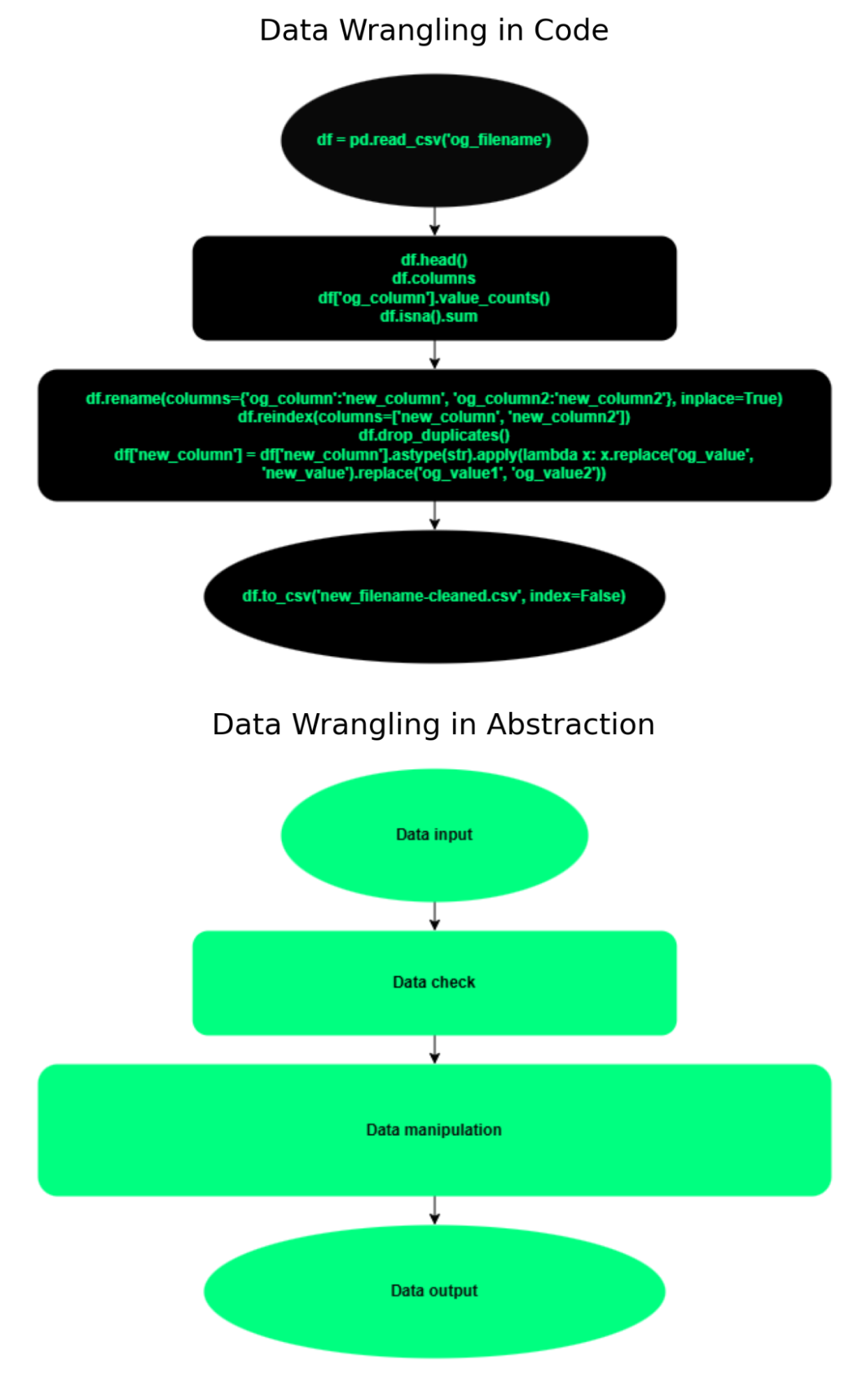
Figure 1— contrasts data wrangling in code with data wrangling
in abstraction,
showing how concrete pandas operations map directly onto higher-level stages like input,
inspection,
transformation, and output.
2 Structure, Indexing, and Alignment as a Core Mental Model
One of the most important mental models data wrangling teaches is structure. Pandas forces you to understand indexing, alignment, and how operations behave across collections of data. Boolean filtering works not because of loops, but because pandas aligns Series by index labels and applies conditions element-wise across columns. Assignments, arithmetic operations, merges, and masks all rely on this same alignment behavior. This is also why logical operators like &, |, and ~ are required instead of and, or, and not—conditions are vectors, not single booleans. Errors such as “The truth value of a Series is ambiguous” stop being confusing once you internalize that pandas operates on labeled data structures rather than positional lists. Once this clicks, you stop fighting the library and start predicting how operations will behave. This structural way of thinking extends far beyond pandas and shapes how you reason about data in any system.
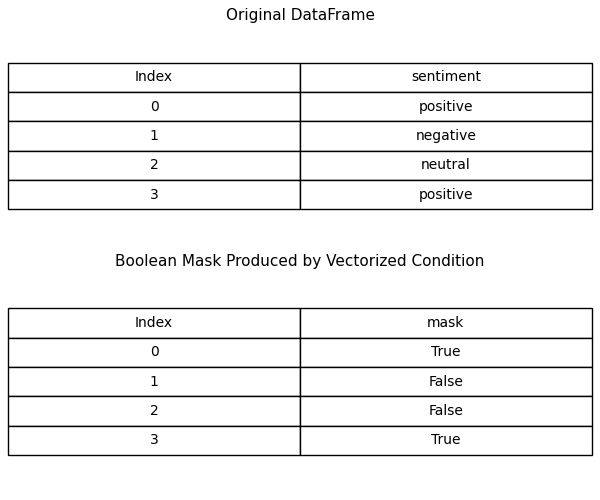
Figure 2— The top table is a DataFrame with an explicit column
and the bottom table
shows the Boolean mask produced by the vectorized conditionsentiment ==
"positive". Crucially, the mask preserves the same
index labels as the
original DataFrame. This visualization highlights that boolean filtering in pandas
operates on labeled data
structures, not positional iteration.

Figure 3— This code demonstrates how a Boolean mask is generated
from a column-wise
condition and then applied to a DataFrame. The expression df["sentiment"]
== "positive" returns a Boolean Series that
retains the
DataFrame’s index labels. When used in df[mask] or df.loc[mask], pandas aligns the mask to
the DataFrame by index. If index labels do not match—either due to mismatched
values or differing
index ranges—pandas may raise an error or, more subtly, perform alignment that
yields unintended
results. Correct filtering therefore depends on maintaining consistent and meaningful
index labels
throughout the data wrangling process.
3 Immutability, Assignment, and Why Things Don’t Change “In Place”
Data wrangling also makes Python’s immutability rules
impossible to ignore.
Strings cannot be modified in place, list elements don’t change unless you assign
back to an index,
and many pandas operations return new objects rather than mutating existing ones. Text
cleaning exposes this
immediately—calling .replace() or .strip() without reassignment does nothing. At the same time,
wrangling introduces performance considerations that explain why this design exists. Python loops are
slow at scale, .apply() can be
expensive, and vectorized operations and
.map() are preferred because they
operate efficiently under
the hood. Pandas string methods, boolean masks, and arithmetic operations all work
element-wise without
explicit loops. Together, immutability and vectorization teach you to think not just
about whether code
works, but how it runs. This performance intuition is foundational—not only for
data science, but for
writing efficient, scalable Python in any context.
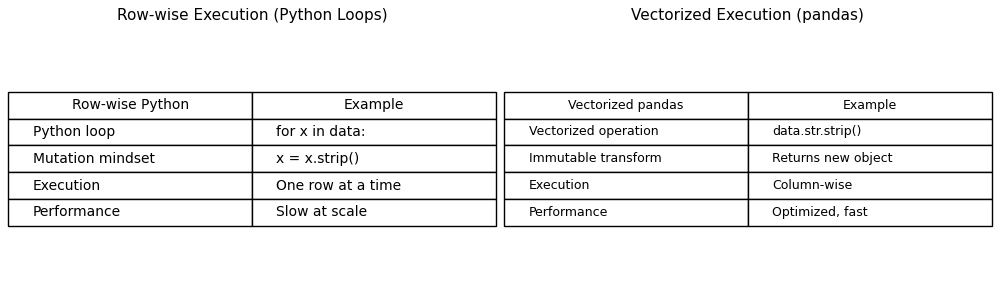
Figure 4— Immutability and vectorization as complementary design principles in pandas. Row-wise Python loops operate on individual elements and encourage mutable thinking, but perform poorly at scale. In contrast, pandas emphasizes immutable, vectorized operations that apply transformations across entire columns at once. Returning new objects enables safe, index-aligned computation while allowing pandas to execute operations efficiently using optimized underlying implementations.
4 Vectorization as the Unifying Principle Between Design and Performance
Vectorization is where all of these ideas come together.
Index alignment explains
how operations apply correctly across rows, and immutability explains why pandas returns
new objects instead
of modifying data in place. Vectorization is the mechanism that makes this design both
correct and fast.
Instead of iterating row by row in Python, pandas applies operations across entire
columns at once, relying
on underlying optimized implementations. This is why boolean masks, string methods,
arithmetic operations,
and comparisons feel expressive and concise—they are operating on vectors of data,
not individual
values. Understanding vectorization changes how you approach problems: rather than
asking how to loop
through data, you ask how to express a transformation at the column level. This mindset
is essential not
just for data science, but for writing Python that scales gracefully as data
grows.

Figure 5— Scalar versus vectorized function application. The figure contrasts row-wise evaluation f(xi)f(x_i)f(xi) with vectorized application f(x)f(\mathbf{x})f(x), illustrating how pandas operates on entire data vectors rather than individual values. This perspective underlies index-aligned operations, immutable transformations, and the performance advantages of column-wise execution discussed in the text.
5 Conclusion
What makes data wrangling such an effective way to learn Python is how naturally it layers foundational ideas. You start by developing a mental model for structure—labels, indexing, and alignment—then confront the language’s behavior through immutability, assignment, and object creation. Together, these ideas set the stage for the unifying principle that underlies pandas performance and expressiveness: vectorization. Each concept builds on the last, not in isolation, but through repeated exposure in realistic workflows.
If you want to truly learn Python—not just syntax, but behavior—data wrangling is one of the most effective paths. It compresses file handling, data structures, immutability, performance, debugging, and transformation into a single workflow that mirrors real-world problems. By the time you’re comfortable cleaning and preparing data, you’ve internalized Python’s foundations in a way that no isolated tutorial can provide.
6 Appendix: Glossary of Terms
Assignment vs. mutation: Assignment replaces a variable or column reference with a new object, while mutation alters an object in place; in pandas, many operations return new objects and require explicit reassignment to persist changes.
.apply() (pandas): A flexible method available on both Series and DataFrames that applies a function across elements (Series) or across rows or columns (DataFrame, via axis). .apply() can access multiple columns and express complex, non-vectorizable logic, but executes at the Python level and is therefore slower on large datasets.
Boolean masking: A filtering technique in pandas where a Boolean Series (True/False values) is used to select rows from a DataFrame; masks are applied element-wise and aligned by index.
Data pipeline: A structured sequence of steps through which data flows, typically from raw input to cleaned and analyzable output (e.g., input → inspection → transformation → output).
Data wrangling: The process of cleaning, transforming, restructuring, and organizing raw data into a format suitable for analysis or modeling, including tasks such as loading data, handling missing values, type casting, filtering, merging, and exporting results.
Element-wise transformation: An operation applied independently to each value in a Series. Both .map() and Series-level .apply() perform element-wise transformations, but .map() is preferred when possible due to performance.
Immutability: A property of Python objects (such as strings) that prevents them from being modified in place; any operation that appears to change an immutable object actually creates a new object.
Index (pandas): A labeled data structure used by pandas to identify and align rows; index labels, rather than positional order, determine how operations such as assignment, filtering, and arithmetic are applied.
Index alignment: The mechanism by which pandas automatically matches data based on index labels when performing operations across Series or DataFrames, enabling correct element-wise operations without explicit loops.
.map() (pandas): A Series-only method for element-wise transformations that applies a function or mapping to each value independently. .map() is more efficient than .apply() because it preserves pandas’ vectorized execution model, but it is limited to single-column operations.
object dtype: A generic pandas data type that can hold mixed Python objects, including strings, numbers, and lists; it offers flexibility but can lead to inconsistent behavior and slower performance.
Performance intuition: An understanding of how design choices—such as vectorization, immutability, and avoiding Python loops—affect execution speed, scalability, and memory usage.
Return type: The type of object produced by an operation (e.g., Series, DataFrame, tuple, generator); understanding return types is critical for debugging chained operations and predicting behavior.
Row-wise operation: An operation that processes entire rows of a DataFrame at once (typically using .apply(axis=1)). Row-wise operations allow access to multiple columns but break vectorization and are computationally expensive at scale.
string dtype: A dedicated pandas data type for textual data that enforces consistent string behavior and enables optimized string operations.
Vectorized operations: Operations that apply a function or expression across an entire column or array at once rather than iterating row by row in Python, improving performance and readability by leveraging optimized underlying implementations.